AIチップ
| TOP | 車山高原お知らせ | 車山高原ブログ | 歴史散歩 | 旅ネット信州 |
リンク
『古事記』は偽書にあらず
古代メソポタミア
古代メソポタミア史
ヒッタイト古王国時代
ヒッタイトと古代エジプト
ギリシア都市国家の興亡
細胞化学
DNA
遺伝子発現の仕組み
ファンデルワールス力
生命の起源
アポミクシス
植物の色素
植物の運動力
遺伝子の発現(1)
遺伝子の発現(2)
元素の周期表
デモクリトスの原子論
相対性理論「重力」
相対性理論「宇宙論」
相対性理論「光と電子」
素粒子の標準理論
太陽系の物理
半導体
AI半導体
AIチップ
|
||||
| 目次 | ||||
| 1)半導体チップとは? | ||||
| 2)AIチップとは? | ||||
| 3)TPUの第4世代モデル「TPU v4」 | ||||
| 4)ライブラリ | ||||
| 5)機械学習 | ||||


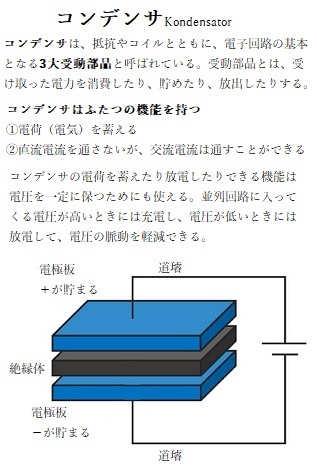 半導体チップsemiconductor chipとは、一般的にはパッケージングされた半導体集積回路Integrated Circuit(IC)の総称として用いられることが多い。集積回路の正体は半導体である。この半導体の基本となるものが、シリコン結晶である。電気を蓄える・放出するという基本機能を持った電気部品であるコンデンサや、トランジスタなどの半導体を実装するためのチップもシリコン製である。これをウェハーと呼ぶ。このシリコンウェーハ上に組み込まれた回路の複雑な集積度によって、すでに100ナノメートル(nm)以下の世界での競争が繰り広げられている。1nmは10億分の1メートルに相当する。
半導体チップsemiconductor chipとは、一般的にはパッケージングされた半導体集積回路Integrated Circuit(IC)の総称として用いられることが多い。集積回路の正体は半導体である。この半導体の基本となるものが、シリコン結晶である。電気を蓄える・放出するという基本機能を持った電気部品であるコンデンサや、トランジスタなどの半導体を実装するためのチップもシリコン製である。これをウェハーと呼ぶ。このシリコンウェーハ上に組み込まれた回路の複雑な集積度によって、すでに100ナノメートル(nm)以下の世界での競争が繰り広げられている。1nmは10億分の1メートルに相当する。半導体チップは、このような極小の単位の世界の中でありながら、2030年の市場規模は100兆円規模を突破し、超巨大マーケットへと成長すると見込まれている。
半導体集積回路(IC)としてパッケージされている電子部品には様々なものがあるが、代表的な電子部品としては抵抗・コンデンサやトランジスタなどの素子が含まれる。近年のICは最小10ナノメートルを下回るほどの精密なものが用いられている。ICのサイズの小型化や高集積化が進むと、これまで付与できなかった機能を更に加えることができるようになる。
この製造技術の進歩は、集積回路の量産化製造と普及を促進し、その普及につれて製造技術は加速度的に進化している。半導体ウェーハ表面に形成されるトランジスタや配線は、非常に精密なため、ウェーハ表面に直接配置することはできない。
そこで、ウエハに「フォトレジスト(レジスト)」と呼ばれる液剤(樹脂・感光剤・添加剤などから構成される混合物)を塗布するコーティングにより多層膜を作り、ダイレクト露光direct Imaging(DI)装置によりウエハに光を照射してパターンを転写することで半導体チップを形成する。
回路の微細化に伴い、欠陥の低減や表面の平坦さなどが求められている。
仕様に基づいた回路を設計し、そのパターニングの原版になるフォトマスクphotomask(レクチル)を作成し、それを基板となるウエハにパターンを転写して半導体チップを製造する。その製造技術の進化と共に、IT素子ばかりでなく、産業界のさまざまな製品の機能も飛躍的に向上させている。
目次へ
AIチップは、AIに特化した半導体チップであり、現在、AIチップが主流となる機械学習や、十分なデータ量があれば、機械が自動的にデータから機械学習し推論inferenceまでするディープラーニングDeep Learning (深層学習)で行われる演算処理を、AIチップにより高速化できるように設計されている。もともと、Graphics Processing Unit(GPU)と呼ばれる製品が画像処理に特化しながら、大規模・高度な計算処理をこなせるという特長があり、その特長が膨大な数の計算を繰り返しながら学習するAIチップの仕組みと、うまくマッチしていたため、GPUがAIチップの開発にも応用されることになった。
GPUは近年人工知能の分野におけるディープラーニングや自動運転、宇宙/気象シミュレーションや医療診断、そして顧客管理やマーケティングのデータサイエンスなど、専門知識がなくても簡単に操作できるため、各産業の重要なテクノロジーに幅広く活用されている。しかしながら、AIチップとは異なり、消費電力や性能の面で課題があった。そこで、AIに特化した半導体チップを作ることで、より消費電力が少なく、高性能ながら細密な素子を開発する動きとなった。その結果、AIチップが生まれた。
AIチップの演算処理は、膨大なデータをもとに学習していく「学習プロセス」と、学習した実際のデータをもとに推論を行って結果を導き出す「推論プロセス」の二つに分けられる。この二つのプロセスでは求められる性能が異なるため、それぞれに特化した形でAIチップが設計された。「学習プロセス」向けでは、学習時間をできる限り短縮できるように高い処理性能が、「推論プロセス」向けでは、実際の現場で使いやすいように消費電力の小ささや、動作保証環境の幅広さなどが求められた。
最初にAIチップとして注目を集めたのは、Googleが開発した「Cloud Tensor Processing Unit(TPU)」という製品であった。
テンソルとは多次元配列のことで、行列の概念を一般化したものであるが、「Google Tensor」は、Google Pixel 専用に開発されたプロセッサであるが、Google が強みとしている機械学習に最適化されたAIチップセットでもある。その搭載により性能が向上し、また機械学習のパフォーマンス向上に注力した結果、カメラや音声入力や翻訳といった機能が革新的レベルまで進化した。
 Googleは「Google検索」「Google翻訳」「Googleフォト」などの自社サービスで「TPU」を活用しているほか、「Cloud
TPU」というクラウドサ
Googleは「Google検索」「Google翻訳」「Googleフォト」などの自社サービスで「TPU」を活用しているほか、「Cloud
TPU」というクラウドサービスでユーザーにAI機能を提供しており、AIの普及に大きく貢献してきた。
「Google Tensor」でも、Googleのクラウドリソースの力を借りる必要はあるが、より多くの情報をデバイス側で処理できるようになり、クラウドへのデータ送信量を低減できるようになった。その性能の向上により、消費電力は抑えられバッテリーは長持ちする。
「TPU」を使用した囲碁プログラム「AlphaGo」がトップ棋士に勝利したことで、世界中がAI技術の進化を強く認識することになった。
「Tensor Processing Units(TPU)」と呼ばれるAIチップは推論処理に特化したチップであり、一方、「Cloud Tensor Processing Unit(CTPU)」と呼ばれるAIチップは、学習処理の高速化を狙って開発された。
第1世代AIチップの代表例であるGoogleのTPUは、同社が、学会
論文や解説ドキュメントなどを大量に公開しているため、AI関連処理に特化したチップの特徴を知る絶好の題材となった。
IT分野で言うワークロードworkloadとは、コンピューティングやシステムなどにかかる処理の負荷の大きさを表す。特に、コンピューターの全処理能力のうち、どのくらい命令の処理が可能か、その割合を示す指標となる。Googleは、現在、TPUを、主に人工知能の推論のフェーズで使っているが、TPUのAI-workloadのレベルは、パソコンの頭脳にあたるパーツCentral Processing Unit (CPU)よりも15~30倍高速で、30~80倍エネルギー効率が高いと言われている。
(CPUは、マウス・キーボード・ハードディスク・メモリーなどのハードウェアやアプリケーションから全てのデータを受け取り、その全ての制御・演算を担当し指示処理をする。)
目次へ
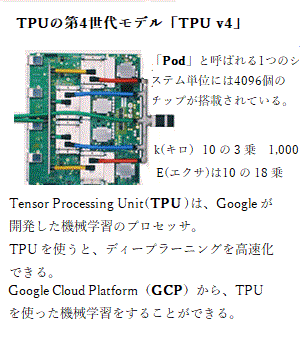
Googleが開発する機械学習に特化した専用プロセッサTPUの第4世代モデル「TPU v4」が、2021年5月18日の開発者カンファレンス「Google I/O 2021」で発表された。
新たなプロセッサは既にGoogleのデータセンターに導入されており、2021年後半にはGoogleクラウドのユーザーが利用可能になっている。「Google I/O 2021」の中で発表された第4世代モデル「TPU v4」は、従来の2倍の性能を持つと言う。
サンダー・ピチャイCEOは、「このシステムは、これまでGoogleに導入されたシステムの中では最速のものであり、当社にとって歴史的な節目となるものである」と
「これまでエクサフロップexaFLOP(コンピュータの処理速度をあらわす単位の一つ)を得るためには、カスタマイズcustomizeされたスーパーコンピュータを構築する必要があったが、我々は既にそれら多くのシステムを導入しており、間もなく数十台のTPUv4ポッドpodが当社のデータセンターに設置される予定である。
(「customize」は、既存のものを特定の人や目的に合わせて改良・改造することを指す。英語での「customize」の定義は、"to modify or build something according to individual specifications or preferences" )
またその多くは90%のカーボンフリーエネルギーで運用される。そして、TPUv4ポッドを、今年後半には当社のクラウド利用顧客にも提供を行っていく」と述べている。
(「Pod」と呼ばれる1つのシステム単位あたり4096個のチップが搭載され、チップは超高速なネットワークで接続されている。これによりPodは1エクサフロップを超える高い演算性能を実現した。)
更に「他のどのネットワーク技術よりも大規模で、チップあたり10倍のインターコネクト帯域幅(それによりブロック転送を処理する速度が決まる)を備えている」とピチャイ氏は強調した。
GoogleはTPU自体は販売しておらず、同社のクラウドサービスの専用機能として利用している。競合のAWS(Amazon Web Services)も、そのクラウドコンピューティングサービスに同様の理由でTrainiumチップとInferentiaチップを開発している。
中央演算装置Central Processing Unit(CPU)は、主に「演算」と「制御」という役割を担うパソコンの頭脳や司令塔と言える重要なパーツである。パソコンが受けた指令はまずCPUで処理され、GPUなど他のパーツに作業が割り当てられろ。
GPUは、CPUのように複雑な計算ができない代わりに、汎用的な処理を行う目的のため作られているため、並列処理concurrent processingに優れており、複数のタスクを同時にこなすことができ、しかも高速で画像の処理が行える。
並列処理とは、コンピュータに複数の処理装置を内蔵して、複数の命令の流れを同時に実行することである。一台のコンピュータに複数のマイクロプロセッサ(CPU/Micro-Processing Unit【MPU】)を搭載することで、複数の異なるデータや命令を並列に処理することでシステム全体の処理能力を向上させることができる。
( ITの用語では、単にプロセッサprocessorといった場合は、コンピュータの構成要素のうち、一定の手順に基づいてデータの演算や変換、プログラムの実行、他の装置の制御などを担う処理装置のことを指すことが多い。そうした機能を持つソフトウェアやシステムなどのことをプロセッサとも言う。扱う処理の種類や対象によって「○○プロセッサ」のように使う。)
元々、マイクロプロセッサ内部には演算や制御を行うための回路は一系統だけ搭載され、一つのプログラムだけを実行していた。並列処理を行いたい場合はコンピュータ内に複数のプロセッサを内蔵していた。
複数のCPUを搭載して並列に処理を行う方式を「マルチプロセッサmultiprocessor」と呼ぶが、複数のプロセッサが同一の基板や筐体に収納され、電子回路で結合されたシステムを「密結合マルチプロセッサ」と言い、一方、複数のコンピュータを高速な通信路で結んで仮想的に一台のコンピュータのように振る舞わせるシステムを「疎結合マルチプロセッサ」と言う。
近年では単体のプロセッサの動作の高速化や回路の微細化などが頭打ちになりつつあることなどから、一つのプロセッサの内部に独立してプログラムを実行できる回路ブロックを複数組み込んでおき、それぞれが単体のプロセッサのように振る舞うように設計された製品が現れるようになった。
一般的なCPUでは、命令の解釈や演算、他の装置の制御などを行う回路を組み合わせたプロセッサコアprocessor coreが1セット入っている。2つ以上のプロセッサコアを単一のICチップintegrated circuit chip(一つのシリコン半導体基板に、トランジスタ・抵抗・コンデンサなどの機能を持つ電気回路の素子を多数作り、それをまとめた電子部品。「chip」は電子回路とデバイスを含む集積回路を収めた半導体の細密な「小片」)に集積したマイクロプロセッサ(MPU/CPU)をマルチコアプロセッサmulti-core processorと呼び、1つのCPUの内部に複数の演算・制御回路を設け、それぞれが独立して処理を実行する方式を言う。
TPUは、Google 独自に開発した「特定用途向け集積回路Application Specific Integrated Circuit(ASIC)」であり、機械学習ワークロードの高速化のために使用されている。「ASIC」は、特定用途向けに「オーダメイドによる集積回路」であり、TPU が、機械学習を主導する Google の豊かな経験を生かして新たに設計した。
Cloud TPU により、GoogleのTPUアクセラレータ ハードウェア上で TensorFlow を使用して機械学習ワークロードを実行できる。AIアクセラレータとは、ニューラルネットワークneural networkにおけるモデル推論処理の高速化(アクセラレーションacceleration)を目指すハードウェアのことである。近年ではAIアクセラレータとして、推論向けの専用の半導体チップも多く登場している。Cloud TPU は、パフォーマンスと柔軟性を最大化するように設計され、研究者やデベロッパー、企業が、CPU、GPU、TPU を利用可能な TensorFlow コンピューティング クラスタを構築する際に役立つ。
(アクセラレーションaccelerationとは、加速度・促進・高速化などの意味する英単語であるが、IT用語では、AIチップなどの機器やシステム、ソフトウェアなどの特定の機能の性能を高め、処理や通信の速度を促進すること言う。また、「ASIC」のような装置や機器を追加して性能向上を促進することを「ハードウェアアクセラレーションhardware acceleration」と言う。)
TensorFlowで使われるTensorと言う概念は、数学上では「ベクトル」や「行列」などといった特殊な情報をまとめて解析するが、極めて難解で複雑な定義となる。
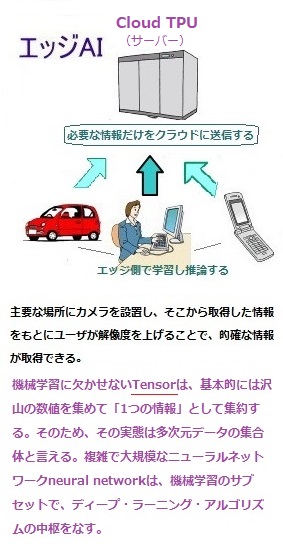
その一方、機械学習に欠かせないTensorは、基本的には沢山の数値を集めて「1つの情報」として集約する。そのため、その実態は多次元データの集合体と言える。複雑で大規模なニューラルネットワークneural networkは、機械学習のサブセットで、ディープ・ラーニング・アルゴリズムの中枢をなす。
「アルゴリズムalgorithm」は、プログラミングによる「問題を解決するための手順や計算方法」全般を指すが、同じ計算を行うなら、より高速に計算できる素子やソフトを研究開発する。
機械学習machine learningのアルゴリズムでは、人間がデータの特徴やパターンを指定しなければAIは学習ができない。ディープラーニングdeep learning(深層学習)のアルゴリズムが、機械学習のアルゴリズムと決定的に異なるのは、「人間が指定せずともデータの特徴・パターンを自ら発見できる点」にある。
ディープラーニングでは、機械学習で必要とされる、特徴量をマニュアルで開発する手順を必要としない。人間の手を必要としない代わりに、データはディープラーニングアルゴリズムに入力され、AIが自動的にデータの出力を決定するために有用な特徴量を学習していく。人間の神経細胞に似たニューラルネットワークが取り入れられているからこそ、ディープラーニングではこのような高度な学習が可能になる。
AIの複雑な処理や分析に必要な特徴やデータを見つけるアルゴリズムは、AIの本質と言っても過言ではなく、極めて重要である。その名称と構造は人間の脳から着想を得て、生体ニューロンが信号を相互に伝達する方法を模倣している。
 次元数が大きく計算の難しい多次元のテンソルが使われていため、複雑で規模の大きなテンソルの計算は難しくなり、通常のCPUでは処理に時間がかかる。そのため並列計算に特化したGPUなどが使われている。
次元数が大きく計算の難しい多次元のテンソルが使われていため、複雑で規模の大きなテンソルの計算は難しくなり、通常のCPUでは処理に時間がかかる。そのため並列計算に特化したGPUなどが使われている。AI開発に欠かせない機械学習のTensorFlowは、Googleがニューラルネットワークの構築・訓練のために開発した機械学習用ソフトウェアフレームワークsoftware frameworkでもある。アプリケーションを開発するとき、その土台として機能するソフトウェアが「アプリケーションフレームワークで、「枠組み」「骨組み」「構造」などといった意味があり、土台となるフレームワークに必要な機能を追加し、アプリケーションの開発を進めていく。
フレームワークとはその言葉通り「構造・骨組み」を意味するように、ソフトウェアやシステムを開発するためのテンプレートのようなものである。基本的に、フレームワークにはコードやDB連動などの機能が含まれている。
フレームワークには、Webアプリケーションの作成に利用される「Webアプリケーションフレームワーク」や、データのソートや文字列操作、数学関数、テストなどのアプリケーションの機能や性能、操作性を向上させるための「ユーティリティ系フレームワーク」などの種類がある。そのため汎用性が高く、機能が充実しながらも、軽量で機能が絞り込まれたタイプなど、多種多様なフレームワークから選択する能力が問われる。
例えば、特定の取引アプリのテンプレートに基づいて開発を進めれば、プログラマーの負担をかなり軽減できる。ログイン機能・決済機能・お問い合わせフォームなどや、通常のアプリに必須となるインターフェースや機能は、フレームワークを使えば、アプリのテンプレートを基づいての開発となり、かなり省力化される。
目次へ
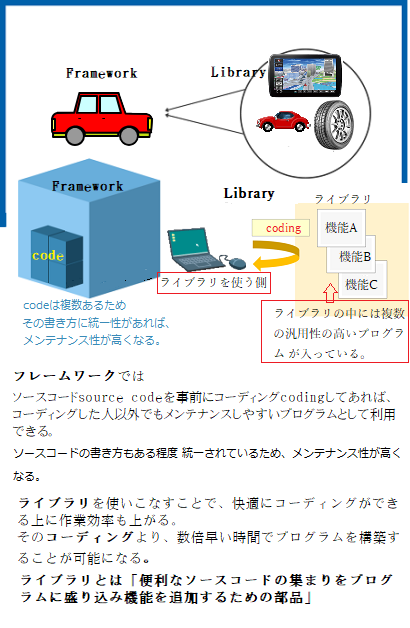
フレームワークに近い「ライブラリ」の略語としては、「lib」という表記がある。ITのプログラム言語には、「ある特定の機能を持つプログラムを定型化して、他のプログラムが引用できる状態にしたものを、複数集めてまとめたファイル」を示す。
汎用性の高い関数function(コンピュータプログラム上で定義されるサブルーチンの一種で、入力された値【引数】を元に応じ処理結果を元に返す数式、あるいは命令の集まり)やクラスソースコードといったものをまとめているのが「ライブラリ」である。ライブラリは基本的に実行するためのものではなく、あくまで便利なソースコードの集まりに過ぎない。そのためライブラリ単体でプログラムを動かすことはできない。
「ライブラリ」自体が単独で機能することはなく、あくまで他のプログラムの部品となることで機能する。だが、ライブラリにはルーチンroutineといった、プログラムの開発に欠かせない多くのデータが集められている。そのため、プログラミング作業の能率を大幅に向上させるためには、「ライブラリ」の利用が極めて有効であるばかりか、その作業内容を大幅に向上させる。
ルーチンとは、特定の処理を行うプログラムの一連の命令の集合体のことである。プログラム内で使用頻度が高い処理、例えば、データベース接続の手続きなどを1つのルーチンとして他のプログラムコードから分離し、その処理が必要な際に容易にプログラム内からルーチンを呼び出せるように、そのソースコードsource codeを事前にコーディングcodingしてあれば、コーディングした人以外でもメンテナンスしやすいプログラムとして利用できる。
プログラム全体の進行を管理する、手続きの呼び出し元のことを「メインルーチン」、プログラム実行中に、メインルーチンや他のルーチンから呼び出されて動作するルーチンを「サブルーチン」と呼ぶ。また、呼び出された側の手続き自体を「サブルーチン」と呼ぶこともある。
規定された全体の枠組みに適合することが開発の前提となる「フレームワーク」とは異なり、「ライブラリ」では、プログラマーが必要とする機能だけを呼び込むことができる。しかも、導入側の開発の大枠を変えることもなく、ライブラリが必要とする機能だけを部分的に読み込むことも可能となり、まして、その導入による既存のプログラムが変更されるリスクが少ないため比較的容易にインストールされている。
フレームワークとライブラリの違いは、プログラマーが持つ「自由度」の差であり、「利用する際の主導権がどちらにあるのか?」に関わる。
フレームワークを使用して開発を進めれば、どこにどのコードを書き入れるのかを決める一定のルールに制約されながら、プログラミングしなければならない。つまりフレームワークを利用する開発では、主導権がフレームワーク側にあるため、プログラマー側の利用の自由度が制限される。
その制約がないライブラリの場合、プログラマーの自由度が高まり、どのコードを使うのかもプログラマーによって決定されるため、軌道に乗れば、ますま独創的な開発を保証する融通性が高まる。つまり、利用するプログラマーが主導権を持つライブラリと、プログラマーの負担を減らしながら開発の効率性と加速化を高めるフレームワークとの違いを理解し、2つの開発ツールを使いこなすことが極めて重要となる!
ライブラリは、人間の脳の神経回路の構造を数学的に表現する手法でもある。そのためオープンソフトウェアライブラリで、機械学習の分野で広く活用されている。フレームワークの最大のメリットは、解決したい問題や分析、意思決定などを、特定の型に落とし込み手順に沿って整理していく、それが共通して利用する側の思考の枠組みとなる。目的のアプリケーションをゼロから開発する必要がないので、開発工程を大幅に短縮できる。その一方、真に自社企業に最適なフレームワークでなければ、そのプログラミングの特有のコードや言語の恣意的活用、そして「アプリケーションの迷宮」などにも迷い込みもする。
 「コンパイラcompiler」は、プログラミング言語で書かれた「ソースコード」を、コンピュータが解釈できる機械語(オブジェクトコードobject code)に変換して実行するプログラムである。
「コンパイラcompiler」は、プログラミング言語で書かれた「ソースコード」を、コンピュータが解釈できる機械語(オブジェクトコードobject code)に変換して実行するプログラムである。プログラミング言語は人間が解釈しやすいように作られているため、そのままではコンピュータに導入できない。そのためコンパイラなどを使い、コンピュータが解釈できる形式のコード「機械語」に変換してから実行する。オブジェクトコードとは、プログラミング言語で書かれたソースコードをコンピュータが直接実行できる形式に変換したコードのことを言う。「compiler」の原義は「翻訳者」。
ITの分野では、ある特定の機能を持ったコンピュータプログラムを他のプログラムから呼び出して利用できるように部品化し、そのようなプログラム部品を複数集めて一つのファイルに収納したものをライブラリという。一般的にライブラリにはオブジェクトコードが格納されているが、それ単体で起動して実行することはできず、他の実行可能ファイルに連結されて利用される。
様々なプログラムが共通して利用される汎用性の高い機能などがライブラリとして開発・提供されることが多く、標準的なライブラリはOSやソフトウェア開発環境の一部として添付されることもある。特定のソフトウェアやハードウェアを利用したプログラムを開発するために必要な機能がライブラリの形でまとめられている場合もあり、システムの開発キットなどの一部として開発者に提供されもする。
まり、アプリケーションプログラミングインタフェースApplication Programming Interface(API)とは、ソフトウェアやそのアプリケーションなどの一部を外部に向けて公開することにより、第三者が開発したソフトウェアとその機能を共有できるようにしてくれるものである。APIは、異なるソフトウェアやサービス間で認証機能を共有したり、複数の利用者がリアルタイムにメッセージを送信するためのチャットchat機能を共有したり、片方から数値データを取り込み、別のプログラムでそのデータを解析したりできるようになる。
(Google Chatは簡単にコミュニケーションを図ったり、短文としてで残しておきたいメッセージを送信したりするのが主な目的であるため、メールよりも気軽にメッセージが送信できる。パソコンはWebブラウザ版とアプリ版が、スマートフォンはアプリ版が提供されている。それにより、コミュニケーションを活性化する効果が期待できる。
また、過去のテキストチャットの内容を検索できる機能もあって、膨大なチャットの中から特定の議題を抽出することも容易になった。)
 高レベルの TensorFlow API は、Cloud TPU のハードウェア上で「機械学習モデル」を実行する場合に役立つ。
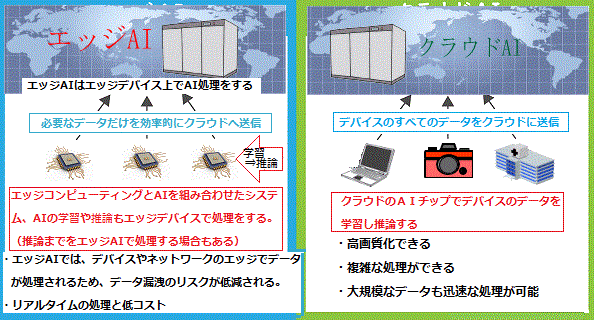
高レベルの TensorFlow API は、Cloud TPU のハードウェア上で「機械学習モデル」を実行する場合に役立つ。現状、AIチップの市場では、「エッジAI」という言葉がキーワードになっている。従来のAIはデータセンターなどのサーバー上で学習や推論が行われており、実際にデータを活用する現場(エッジ)との距離が遠かった。
そのことで、
① データ通信量が膨大になる
② エネルギー消費量が増える
③ リアルタイム性が損なわれる
近年ではAIチップを関連機器にセットすることで、AI機能をエッジ側に設置し、現場で即座に推論ができる環境を整えるという「エッジAI」と呼ばれる製品が増加している。これにより、データを収集し、処理するためのコンピューティングを、データを生成する端末やデバイス、例えば測定器やカメラ、センサーなどで行うようになった。処理用のサーバをデバイスと同一LAN上に配置する方法などもあるが、AI処理する度にインターネットを使って、データを中央のクラウドやデータセンターに転送することなく、即座に利用することが可能になった。「エッジAI」により、リアルタイムでのデータ処理や、データを転送することで生じる通信コストを減らすことができる。
学習したAIモデルをもとに「エッジAI」Iが現場で推論を行い、大きな負荷がかかる学習だけをサーバー上で実施すれば、「エッジAI」の普及により、迅速かつ高度な判断が求められる完全自動運転車のような技術が現実化する。
AIチップの各メーカーは、このエッジAIを視野に入れて開発に取り組んでいる。大手企業だけでなく、ベンチャー企業もAIチップ市場に続々と参入しており、莫大な投資マネーも動いている。日本でも有望なベンチャー企業が誕生しており、大手企業や研究機関と連携しながらAIチップの開発を進めている。
AIチップの登場によって、半導体業界がさらに活性化することになる。 AIチップの市場はまだまだ発展途上にあり、さまざまなメーカーが切磋琢磨しながら市場を盛り上げていく。これからの時代も作っていくであろうAIチップの動向から、目を離せない状況が続く。
エッジAIの市場に参入している主要企業には、Google・Microsoft・Intel・Amazon・NVIDIA(エヌビディアコ)・Qualcomm(クアルコム)などがある。
目次へ
近世哲学の祖として知られるフランスの哲学者ルネ・デカルト(1596年 - 1650年)は、動物を機械のように捉え、その行動や反応を因果関係で解釈できるとする「動物機械論」を唱えている。
1637年に公刊された『方法序説』で「 時計などの機械は部品の組み合せで規則的な動きをするが、 動物も同様に自然が与えた部品の組み合わせによって機械的な行動をとる。」
 機械学習machine learningは、ある程度まとまったデータを基にして、決められた方法で学習し、予測や推論を行う。機械学習モデルを構築するために用いられる、最初の一定の形式に整えられたデータの集合体こそが、「機械学習モデル」を構築するために用いられる「学習用のデータセットdata
set」である。最初に使用され且つ、最も規模が大きいという特徴から「訓練用データ」とも「大規模データセット」とも呼ばれる。もし、それが不適切なデータセットであれば、実行後のアウトプットに基づき意思決定がなされるため、重大な損失が生じる可能性が高まる。
機械学習machine learningは、ある程度まとまったデータを基にして、決められた方法で学習し、予測や推論を行う。機械学習モデルを構築するために用いられる、最初の一定の形式に整えられたデータの集合体こそが、「機械学習モデル」を構築するために用いられる「学習用のデータセットdata
set」である。最初に使用され且つ、最も規模が大きいという特徴から「訓練用データ」とも「大規模データセット」とも呼ばれる。もし、それが不適切なデータセットであれば、実行後のアウトプットに基づき意思決定がなされるため、重大な損失が生じる可能性が高まる。データセットの内容は、音声認識や画像認識、自然言語処理など分析したいデータによってさまざまであるが、その内容が質・量ともに充実していれば、機械学習の精度や、汎用性も向上する。
テンソルは、多次元データの集合体である。AI(人工知能)による画像認識・音声認識・自然言語処理、そして言語翻訳などのディープラーニング(深層学習)には不可欠なデータセットとして広く利用されている。テンソルを構成する膨大なデータをAIに反復学習させ、パターン化に成功すれば、有用なシステムやプロダクトproductが完成される。
(IT用語では、パソコンやスマートフォンなどに利用されるソフトウェアやアプリなど、ハードウェア以外の製品を「プロダクト」と呼ぶ。また、ソフトウェアによって提供されるオンラインサービスのことをある種の商品とみなしてプロダクトと呼ぶこともある。)
プログラムで処理されるデータセットには、画像データセットや動画データセット、音声データセットやテキストデータセットのほか、自然言語処理用のツールを含むデータセットや、機械翻訳システムの構築に利用できる多言語間の翻訳文を構造化した対訳コーパスTranslation Corpus(コーパスとは、日本語や英語などの自然言語の文書を大量に集めたもの)、更に経済・金融や医療や観光などのデータセット、実にさまざまなジャンルに及ぶ。
データセットとは、何らかの目的や対象について収集され、一定の形式に整えられたデータの集合であり、そのデータセットを構成する1件ごとのデータの組み合わせを「レコード」や「データポイント」と呼ぶ。一件の「レコード」には複数の要素が含まれている。データの表す内容に応じて数値や文字列、画像や動画、音声などを組み合わせて構成される。機械学習では集めたデータセットからレコードを1件ずつシステムに入れて計算させることで、対象についてのモデルを構築する。
 データセットでは、自身でアンケートを調査し独自のデータを収集することも可能であり、その場合、工数は増えるが、費用が抑えられる。独自で集めることが難しい場合は、要望に合わせては発注ができるクラウドソーシングcrowdsourcingを活用したり、信ぴょう性の高いデータを提供してくれる専門会社と提携したりする。データ収集を外注すれば、独自で集める場合に比べて社内工数を大幅に削減できる。
データセットでは、自身でアンケートを調査し独自のデータを収集することも可能であり、その場合、工数は増えるが、費用が抑えられる。独自で集めることが難しい場合は、要望に合わせては発注ができるクラウドソーシングcrowdsourcingを活用したり、信ぴょう性の高いデータを提供してくれる専門会社と提携したりする。データ収集を外注すれば、独自で集める場合に比べて社内工数を大幅に削減できる。機械学習を行う際には、その目的や背景、仮説や予測などを十分検討した上で、どのような内容のデータセットが必要となるか考えることが極めて重要となる。「AIチップ」により、大規模データセットを処理できるようになり、その膨大な量のデータを有効なライブデータlive data(実行ファイルを実際のWebサーバー上に配置して、利用できる状態にする)として、それらを分析することでリアルタイムに意思決定することが可能になった。
機械学習machine learningは、大量の「学習データ」の統計的分布から、より自動的に改善するコンピューターアルゴリズムcomputer algorithm(algorithmとは、問題を解くための手順)を構築する。そのために、大量の「訓練データ」もしくは「学習データ」の統計的分布から、さまざまな組み合せパターンを作り出す「「推論モデル」に当てはめて、その結果を導くプロセスを形成する。
AI の一種として考えられる、生物の神経細胞をモデル化した人工ニューロンartificial neuronを使用して、その人間の情報伝達組織を模倣することにより、画像や音声などの抽象データに対応する認識能力や自然言語処理機構を作ろうとした。
「機械学習モデル」とは、特定の種類のパターンを認識するトレーニングのためのファイルでもあり、機械学習は、開発者が厳選したデータセットに「機械学習モデル」を提供することで、「機械学習モデル」の分析に必要なデータタイプに関する情報をすべて「学習」することになる。それに培われたライブデータ化した「推論フェーズ」で解析予測しながら、実行可能な結果を生成するプロセスを形成する。
「機械学習モデル」のトレーニングは、データセットによって行われるが、それらのデータについて推論が可能となるアルゴリズム能力を向上させる。
「機械学習モデル」を使用してトレーニングを完了すると、「機械学習モデル」がこれまで見たことのないデータも含めて推論し、そのデータに関する予測の精度を上げていく。
ディープラーニング(深層学習)とは、あらかじめ定義されたデータセットを分析し、そのプロセスにおいて、何度もエラーを繰り返すことで、それらが何を意味するのかを予測できるまで「学習」することで、最終的に精度の高い結果を導くことができるようになる。
 例えば、顔の表情に基づいてユーザーの感情を認識できるアプリケーションが構築できると、特定の感情にタグ付けされた複数の顔の画像を「機械学習モデル」に提供して、それによるトレーニングを重ねることで、ユーザーの感情を認識できる「機械学習モデル」の領域を拡張させ、それを自動化することにより、一貫性のある結果が容易に、しかも迅速に得られるようにする。
例えば、顔の表情に基づいてユーザーの感情を認識できるアプリケーションが構築できると、特定の感情にタグ付けされた複数の顔の画像を「機械学習モデル」に提供して、それによるトレーニングを重ねることで、ユーザーの感情を認識できる「機械学習モデル」の領域を拡張させ、それを自動化することにより、一貫性のある結果が容易に、しかも迅速に得られるようにする。深層学習deep learningは、機械学習machine learningの手法の1つでもある。機械学習では、どのような学習をしていくかについては構築者が決定し、学習と分析の効率化を図っていくため、人間がデータの特徴を判断する。そのためか、深層学習よりは学習に時間がかからない。
しかしながら、.深層学習の方は、データの特徴を判断するために、何を学ぶべきなのかも機械が判断するため、人間にとって極めて抽象的な問題であっても、その解決を効率化してシステム化もする。ただし学習には大量のデータが必要となり、学習を効率よく進めるには高い処理能力を持つコンピュータが必要不可欠となる。
AIサービスについて、「AI、機械学習、ディープラーニングそれぞれの違い」や「機械学習とは何か? そもそも統計とどう違うのか?」という疑問が生じる。これはAI関連の用語が突如大量に現れたことにより、未だ言葉の定義や意味合いが整理されていないからである。
マーケティング業界の中でもAI活用に至るキーワードは、 AIの三大分類である AI > 機械学習 > ディープラーニング をまずは押さえておかなければならない。
 「AI、機械学習、ディープラーニング」の3つの関係を図にすると左図のようになる。最も広義な領域を持つのがAI(人工知能)であり、機械学習とディープラーニングを内包する概念である。
「AI、機械学習、ディープラーニング」の3つの関係を図にすると左図のようになる。最も広義な領域を持つのがAI(人工知能)であり、機械学習とディープラーニングを内包する概念である。人工知能(AI)の研究は、数学者アラン・マシスン・チューリングAlan Mathison Turingが、1936年、23歳のときに「計算可能数についてOn Computable Number」という論文の中で提示されている「チューリングマシン」が嚆矢であった。チューリングが頭の中に描いたのは「仮想機械」の段階であったが、「人間が頭脳を使って行う計算を、機械に作業させたらどうなるのか?」という発想から、現代的なコンピュータの基本的な動作モデルを創出した。これが現代のコンピュータの原理になったと言われている。しかし、チューリングの意図は、「完全な知能の定義を提唱」したものではなく、「知能とはなにか」という抽象的な問を、さまざまな具体的な問の中で解析breakdownしたことにあった。
1950年代後半~1960年代、コンピューターによる「推論」や「探索」が可能となり、特定の問題に対して解を提示できるようになったことがブームの要因となった。米国では、「自然言語処理」による「機械翻訳」に傾注した。しかし、当時の人工知能(AI)では、迷路の解き方や定理の証明のような単純な仮説の問題を扱うことはできても、様々な要因が絡み合っているような現実社会の中の課題を解くことはできないことが明らかになり、一転して冬の時代を迎えた。
その後の経過はブームと冬の時代が交互に訪れてきた。現在は第三次のブームとして、脚光を浴びているAIは「知的な機械、つまり、知的なコンピュータプログラムを作る科学と技術」を中心概念として広い定義がなされている。
 「機械学習Machine Learning」がAIチップに内包され、特定のタスクをトレーニングにより機械が実行する。「深層学習deep learning(ディープラーニング)」も、AIチップの一部であり、また機械学習の1種である。機械学習の「アルゴリズム/手順」の種類は実は様々であるが、その中の1グループがディープラーニングと言える。
「機械学習Machine Learning」がAIチップに内包され、特定のタスクをトレーニングにより機械が実行する。「深層学習deep learning(ディープラーニング)」も、AIチップの一部であり、また機械学習の1種である。機械学習の「アルゴリズム/手順」の種類は実は様々であるが、その中の1グループがディープラーニングと言える。特に認識系AIチップや会話系AIチップの活用分野において、今や人による特徴定義を不要とする、以前からある他の「機械学習アルゴリズム/手順」よりも高い精度を実現する、いわゆる第三次人工知能が火付け役として登場している。
AIチップには、AIの演算処理を高速化するための半導体を含む。AIチップにより機械学習による画像認識や音声認識、ディープラーニングによる膨大な演算処理が行われる。画像処理やAI処理において、現在も、高性能なGPU(画像処理装置)が必要となっており、学習用では、GPUがほぼ標準化されつつある。
一方で、学習用と推論用とではスペックspec(specificationの略語、IT用語では【属性を表す要素の集合】)も異なり、特にエッジ向けの推論用のAIチップは、IoT(Internet of Things)と共に現場でのAIを処理するデバイスの重要素子となり、「演算能力」だけではなく、「小さい消費電力」や「広い動作保証温度」、そして「長い供給期間」などと言った優位性が、デバイスへの組込み実装には不可欠となっているのが現状である。
自然言語を理解するAIにより、質問に自動応答するクラウドサービスのAIチャットボットchatbotが実現し、社内外のさまざまな問い合せに対応するカスタマーサポートや社内問い合わせ業務などの自動応答を可能にした。
(「チャットボットchatbot」とは、「チャットchat」と「ボットbot」を組み合わせた用語で、人工知能を活用した「自動会話プログラム」。
「チャット」は、インターネットを利用したリアルタイムコミュニケーションのことで、「Chatwork」や「Slack」を介して、ワンタッチでつながる「遠距離会議」などができる。
「ボット」は、「ロボット」の略で、人間に代わって一定のタスクや処理を自動化するためのプログラム。スマホアプリに組み込まれれば、情報管理を支援する機能やアプリケーションなどに便利なツールになる。)
AIの三大分類「タスクの幅」・「知能のレベル」・「分析技術」を知った上で、「あらためて機械学習とはなんだ?」について話を進める。
(ここで言う機械学習には繰り返しになるがディープラーニングを含んでいる。)
汎用型AIは複数のタスクに対応できる(「タスクの幅」 )。AIの技術は進歩し続けているが、人間の脳に近づく汎用型AIは未だに研究段階にあり、実用化されていない。特化型AIの方は、特定のタスクに特化したAIで、その分析力は非常に高く、特定の分野に限れば、人間の能力を超えるケースも稀ではない。近年実用化されているAIは特化型が大多数であり、お掃除ロボットや将棋などさまざまな分野で活躍している。
特化型AIは、「言語」・「音声」・「画像」・「制御」・「推測」など、分析対象のデータ領域やアウトプットする能力ごとに得意分野が絞られている。そのため得意分野以外では自ら思考したり学習したりができない。
 |
| 6月のコバイケイソウとレンゲツツジ |
 |
| 秋の蓼科湖 |
「強いAI」は、事前に組まれたプログラムを元に、総合的な判断や意識を持つAIを指す。フィクションの世界に登場するロボットなどは、あらかじめプログラムされていないケースにも対応ができ、人間のように感情を持ち、柔軟に思考することで自立的に問題を解決する。
「強いAI」は、将来的に感情を持つようになるという専門家もいるほどである。しかし、強いAIが完成するまでには多くの技術的な課題が立ちはだかり、現時点では実用化に至っていない。
「弱いAI」とは、所定のタスクを処理するAIである。弱いAIは機械的にタスクをこなすため、イレギュラーな事態が起きると、弱いAIでは対応ができない。つまり本当の意味で人工知能のレベルにまで達していない。近年、普及がめざましいAIは、大多数が自ら考えてタスクを行うことはできないため、「弱いAI」に分類される。
「分析技術」 ルールベースとは、人間が設定したルールをもとに状況を判断する「分析技術」である。設定・入力されていないルールであればAIは分析を実行できない。AIの分析技術にはさまざまな種類があり、性質や用途によって分類される。ルールベースのAIは問題解決や推論など論理的な処理に適している。入力するルールが有限であれば、ルールベースのAIは有効と言える
。
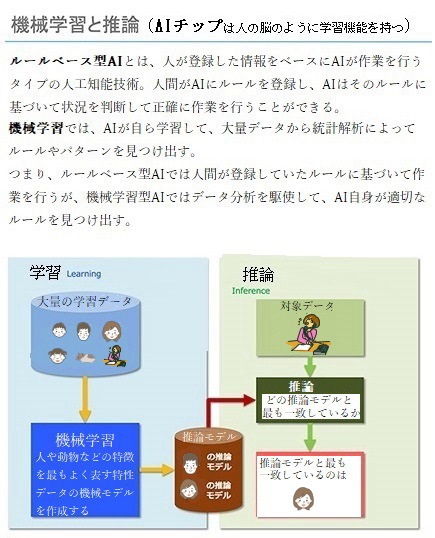
機械学習がどういったものかをまとめたのが左上の図だ。 機械学習は大きく2つの側面から見て定義するとわかりやすい。
① 機械学習は、「特徴」をつかみ「法則化」する。
② 機械学習は、「法則化」を「自動化」する。
1つ目の側面から見て、機械学習はその名の通り、学習する機械(マシーン)だ。この機械は、データから反復学習をし、学習結果を法則化する(法則化をモデル化とも呼ぶ)。また、この反復学習からある事象(コト・モノ)の「特徴」をつかむのが最大のポイントでもある。丸暗記的に全部覚える、というものではなく、沢山のデータからある事象の傾向・クセといった「特徴」を捉えにいく。うまく事象の特徴を捉えられると、それを次回以降にも利用できる「法則化」に昇華させる。
そして、事象の特徴をつかんで法則化できた状態を「自動化」し、以降の「再現性」を確立するのが2つ目の側面である。学習する機械であることからもわかるように、機械学習はシステムそのものだ。ただしシステムといっても、ルールベースの条件文を数万行と記述していくようなシステムではなく、法則を自動化する部分において、ノンプログラミングでシステム化を行う。
もちろん機械学習を動かす上で、様々なプログラムは必要であるが、「特徴から生まれた法則性を自動化する」というコア部分は、ルールベースのプログラミングで構成されるものではない。
データを分析する方法の1つである機械学習は、データから、「機械(コンピューター)」が自動で「学習」し、データの背景にあるルールやパターンを発見する手法である。近年では、学習した成果に基づいて「予測・判断」する「推論」に主眼を置く。
機械学習の類義語として、「人工知能(AI)」や「ディープラーニング(深層学習)」がある。「人工知能」を実現するためのデータ分析技術の1つが「機械学習」で、「機械学習」における代表的、有用なな分析手法が「ディープラーニング」と言える。その機械学習が主眼を置くのが「予測・判断」する「推論」の精度である。
AIが登録された大量データをルールに基づき、データの背景も含めて正しく統計解析し、新たなルールやパターンを見つけ出す「学習」により、精度の高い「予測・判断」する「推論」ができるかどうかを重視する。
機械的に予測精度の高いモデルを構築するための予測モデル自体が妥当性や整合性を欠く場合もある。一方で、優れた「機械学習」によって、従来の「統計学」による仮説検証型のデータ分析では見つけられなかった「新しい発見」や「高い精度」の予測モデルが構築されるようになった。
その後、AIチップ用に開発した学習モデルを、実際のWebサーバー上に配置して、「推論」に利用できる状態にする。
目次へ